Voraldo13
First thing, I've decided to change the naming convention for the Voraldo project to more accurately reflect how many times it has been rewritten. In the past I have just been bumping by 0.1 each time, but that really doesn't make sense. Most versions have been substantial rewrites, with very little code carried between versions. This is in part neccesitated by how much changes in the base NQADE template between versions, but is also needed when I make significant architectural changes to the Voraldo code. I usually don't like making these changes in place, so it turns into a rewrite. Since v1.0, I have used the current version of NQADE as a starting point for each version. If I was smart, I'd figure out a way to encapsulate the entire engine independent from the application code, set it up as an updatable submodule or something, but we're not quite there yet.
New Interface
Menus
First things first - I completely redid the menus from scratch. They're not attached to the side of the window anymore. I have Imgui configured to spawn platform windows, so they can be dragged around and can pop out, they can operate outside the main window. I was going to try to do something where I encoded all the interface elements as JSON, and then parsed that to create the layouts, but that didn't happen yet. I am still planning on doing this for next version, this was kind of getting the ideas together for the structure. Basically this is going to make it easier to write the menu layout code like a parser, and then define the menu component for each of the operations as a list of interface elements. Each operation will also include information about the associated shader, the invocation structure, the bindset, and a few other pieces of information. There may be a couple operations that will require manual layout, but hopefully I'll be able to hit most of them with this scheme because I think it will make the code simpler.
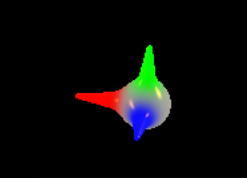
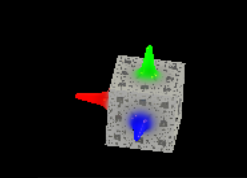
Trident
One of the other nice things I added was a configurable raymarched orientation widget, the Trident. Previous versions have been rendered with API geometry. This is raymarched, with the result stored in a small texture each time the rotation state of the block changes. Any other frame, the contents of this texture is just copied on top of the output texture. I will explain the new VSRA rendering architecture later, but this is one of the steps that comes after the voxel raymarch data has been prepared. The default Trident is a sphere with a couple of iq's rounded cone primitives, but you can also set it up to show with a menger sponge as the center element. You can see both above, and it's easy to add in new ones ( maybe an XOR to match the default voxel block? ). The Trident indicates where the positive x, y, and z axes are pointing at any given rotation state of the block, to assist in placement of primitives and configuration of lighting operations. A nice addition to this would be multiple samples per pixel during the raymarch step, in order to get some anti-aliasing on the finer detail features and edges, since they come through pretty rough in this implementation.

Timing Display
Placed right below the Trident is the frame timing display - this is rendered with my new text renderer, and updates each frame, with a few frames of smoothing. It's the same as the one in the default NQADE template, so it's not particularly new or interesting. The timing value comes from SDL_GetPerformanceCounter() and SDL_GetPerformanceFrequency().
This text overlay may eventually include a dropdown console, in order to show more internal state information like htop does, and allow for text input of commands. We'll see what this entails, I think it would be a cool feature to add to the interface, maybe even something to add to NQADE itself before starting the next rewrite.
Click and Drag
Something else I improved on was the click and drag interaction - I was able to get the cursor deltas to much more closely match the movement of the mouse, so there is less of a disconnect between the input and what you see as the user. Left click and drag pans the image, with the mouse deltas updating the x,y offset for the renderer. Right click and drag rotates the block - the x delta does the same rotation as the left and right arrows on the keyboard, and the y delta does the same rotation as the up and down cursor keys. These are all quaternion based rotations, so it rotates about the apparent screen x and y vectors to keep things in line with user intent.
Fonts
Last thing in the interface changes is that I figured out how to use different fonts in Imgui. I have a pile of different fonts in the engine, some to represent different Star Trek race languages - Imgui supports otf and ttf fonts, it loads the glyphs into a table which it then uses to render the output, so we have a lot of flexibility here. You can set up multiple fonts at startup, and then push and pop them for different interface elements the same way it does a lot of other more advanced styling stuff. I set up a second font for the titles, you can see it in the screenshots above. This is fairly basic, but I had never really experimented with multiple fonts in Imgui before.
Utilities
Depth of Field
Several new utilities were added in this version, in a couple of different areas. First one I want to mention is the realtime thin lens depth of field ( DoF ) implementation that I added to the renderer. Usually for realtime applications, DoF is implemented as a depth-dependent blur, where pixels outside of a certain depth range are blurred to simulate the effect of a lens's ability to focus on a certain range of depth. In the thin lens model, there is a real, ray-based simulation of this behavior that must be accumulated over multiple samples before it resolves. If you're curious about how this is implemented, this section of Raytracing in One Weekend has a pretty good coverage of the basic concept. I was surprised that this was so practical for Voraldo13, because this is usually something reserved for offline renderers, due to this requirement. It definitely slows things down, and the ray divergence is rough on caches, so the frame time will spike as high as 250ms - but this really is not bad for the results it produces. I have several samples here, you can click through to see them full size.









Different Types of Screenshots
There are three types of screenshots which can be taken. We will get into the specifics on what these buffers are in the rendering architecture section, but the first one takes data directly from the accumulator. This is the averaged data frame-to-frame, the accumulated pixel samples, which are blended to produce the image data for the block. This has to be mapped to LDR for output ( until I can integrate something to write EXR format images, for higher dynamic range and floating point output ) - this means we loose data via narrowing conversion from float to uint8, and there's no way that it can be recovered without the original block data.
In order to get more reasonable data for output, we can look at grabbing data from a different stage of the process. By taking from the texture which is used for presentation, we can get the data, after it has been tonemapped and gamma corrected. This means that we have already done the HDR->LDR conversion and any postprocessing, and it's ready to be encoded as an 8-bit per channel image. This emphasizes the role of the tonemapping curve in the HDR->LDR conversion. The third version of the screenshots that the engine supports is taken directly from the output screen's backbuffer, via glReadPixels. This has the LDR output, but also includes the Trident and the timing display, as well and any imgui windows that are present.
Adjustable Temporal Parameters
In v1.2, there was a constant blend factor that mixed each new frame's data with the running average. In this version, I have that attached to a slider which is under the rendering settings, and allows me to adjust the goal of this blending. For general purpose usage, we can leave it at the default of 0.618, an approximation of the golden ratio, to minimize ghosting, but if we want to let it sit and accumulate samples across many frames to converge to a result, that can be set to 0.99 or more. Additionally, we can adjust here how many frames this runs after the last input event that changes the state of the rendering model. When the block pans or rotates, something is drawn, lighting changes happen, or other events which neccessitate an update, a counter resets. We then render some configurable N frames, which allows for an image to accumulate since this state change.
For example, if I want realtime interaction, I would leave this set at the default value of 8 - this means that it will run the actual heavy rendering shader for 8 frames after the last input event that changed the rendering state. When I want to accumulate the DoF and the jittered pixel samples across many frames, I might set this value to 200, and also set the blend factor to 0.99 at the same time. This means that it will accumulate 200 frames, each one being blended with the history weighted at 0.99 - this value is static, instead of changing with the number of samples, so that I have a little more flexibility in terms of user intention. By having this adjustability, I have a tradeoff between speed and quality, that can be adjusted on the fly at runtime.
The accumulation is not perfect, and we will still see shadows from the contents of the data block if the parameters are not set in reasonable areas. This is particularly apparent when the lighting values go to unreasonable levels, e.g. point lights considering very small distances when approximating the inverse square law, since those values will become very large, and will take a long time to average back down to reasonable levels. This is an area that may require a bit more work in the future, maybe some kind of clamping of the values in the accumulator would help. It's a bit of a difficult situation because the current implementation basically supports arbitrary ranges for lighting values, within the capabilities of IEEE 754 floats - a solution for this would require some thinking.
Masking Changes
The mask by color stuff has been all gathered into one place, with invert, unmask all, and mask by data all on one page. This makes it easier to manipulate the state of the mask, from a central location. Fairly straightforward, this is basically just an ergonomics change.
Shapes
Heightmap
Only really one big addition here - a few operations could only be applied in one direction, when they would have been much more flexible and general purpose if I could do them in all 6 ( +/-x, +/-y, +/-z ). The first of these was the heightmap - in the previous version, it was hard coded to only consider the height values along the positive y axis. I was able to change this to consider all the possible orientations, and was able to do some interesting little operations where I would start with some data in the block, and then cut into it from each face, with a newly generated heightmap each frame.
The user shader implementation on this version lacked polish, and that's something I'm planning on improving in Voraldo14. The goal here is to have something as easy to work with as the user shader in v1.2, but also provide some more utilities via included headers. Specifically, using stb_include.h, I am able to use the standard #include statement, as I would be able to in any standard C code. This makes it easier to include things like hg_sdf, my collection of tonemapping curves, etc, etc.
Lighting
Cone Lights
This is one that had been on the list of things to implement for quite some time, and I'm not really sure why I hadn't gotten around to it. It's a quite straightforward extension of point lights, using the dot product of a direction vector with the offset between source and the voxel under consideration. By mapping the value of the dot product using smoothstep, I'm able to give a variable width cone, and the rest of the parameters basically match what the standard point lights were doing. You can see a simple example of the cone lights in action here. Click through to see them full size.




Fake GI Changes
The implications of this change are quite a bit more subtle, and hearkens back to the method I learned from Brent Werness now a couple years ago, from his Voxel Automata Terrain code - this has been included in the past couple versions of Voraldo. I have extended the method in a significant way, to make it more flexible for my purposes - as I mentioned for the heightmap, this is another place where I went from a single possible orientation to 6 possible orientations. This opens up a lot of possiblities, because the previous implementation could only consider the "up" direction to be in line with the positive y axis. By now allowing it to go in the positive and negative direction, on the x, y, and z axes, I can now create much more interesting lighting on models. For example, I can apply this operation with an orange sky color on the positive y axis, to give some diffuse lighting in that direction - this will leave the negative y axis dark - and then apply it along the negative y axis in purple - this creates some interesting contrast, as it it blends together with varying intensities in the x and z directions.
New Rendering Architecture
High Level Structure
This is the new graphics pipeline for NQADE - the Very Sexy Rendering Architecture ( VSRA ) is a compute-based affair which uses two different image buffers. The first buffer is a higher precision floating point buffer, which acts as an accumulator for whatever rendering operation is happening. I like to keep it fairly general, because NQADE is very much general purpose - I use it for a number of different rendering techniques and I need it to stay pretty flexible. Once the data for a given frame is prepared, the data from this buffer is tonemapped, gamma corrected, and stored in a low dynamic range, 8-bit per channel buffer, to be presented to the screen. The present buffer is mapped to the screen and drawn with a fullscreen triangle. It's simple, but that's a feature. Any postprocess operations run on the LDR output directly.
Dithering Postprocess
I support two different types of dithering on this project. The first of these is the same as what I described here, where the color is converted from RGB to another color space, the precision is reduced, and then converted back. The second is palette based, which is more in line with the original intent of this article, which I based my thresholding logic upon when writing my previous dithering implementations. There is a bit of an issue here, with variable size palettes, and the shader to do the actual dithering can become really quite slow. I haven't spent a lot of time diagnosing the cause of this, but I have a large collection of palettes that I can pack into a small 1d texture and iterate through to consider it as palette data. These came from data I acquired from a siterip I did a few months ago of lospec, which collects user-generated color palettes.
You can see a couple results of this dithering process below. Different palettes have different numbers of colors, and different levels of precision reduction quantize the color to different color counts, in the same way. This is an aesthetic operation, but it can also reduce the size of PNG output, by reducing the color count that needs to be represented in the file. PNG scales with the number of distinct colors represented in the data, and for high color counts and smooth gradients, you can start to see very large files. Click through to see full size.


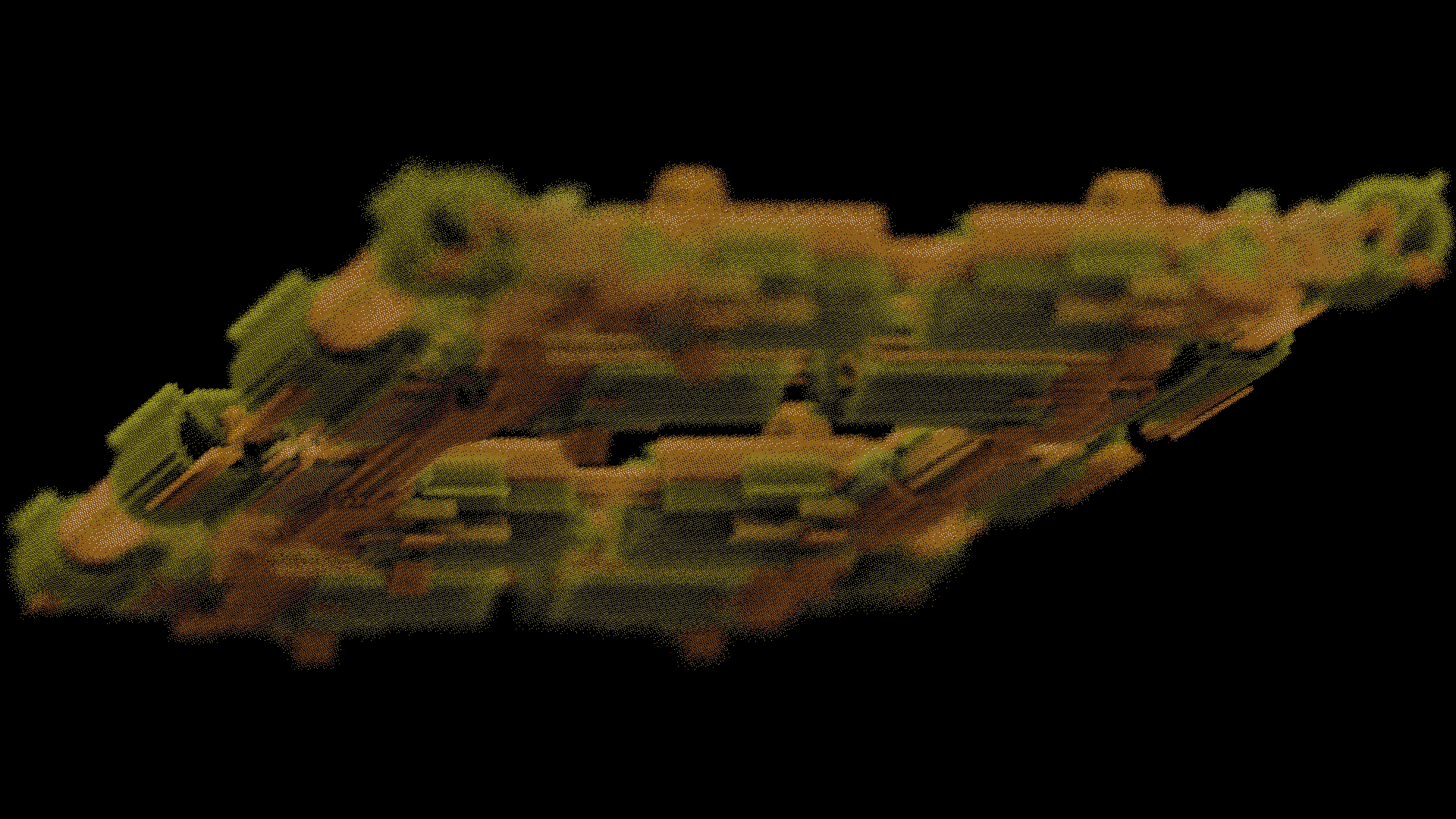



Future Directions
I have decided to redo this project again, and will start on Voraldo14 soon - I'm not particularly set on this menu format I set up for 13, and I think there's a lot of room for improvement. A lot of the code from Voraldo13 can be reused, but I do want to rework a lot of things I implemented for this iteration and include some of the more recent additions to NQADE.
One of the big things I want to experiment with is something along the lines of photon mapping, or something like a 3d analog to what I did in this forward pathtracing project. The current lighting solutions are pretty capable, if you're willing to play around with them, but I don't currently have any way to represent surface normals or material properties like index of refraction. I have heard it suggested now several places that you can calculate normals directly from the voxel data by taking the gradient of the alpha channel ( specifically, it was in the context of 16-bit DICOM data, so you have a lot more information available - we're going to have to see how it works with the 8-bit range of the alpha channel ), so that's something I want to maybe try as well.