Markov Chains for Text Generation
This was a quick weekend project, using some templated STL types. Given some body of text as a corpus, you can quickly generate an arbitrary quantity of text that uses the strings from your input to construct something that vaguely resembles human-generated text. In the repo, I have included some interesting bodies of text to generate models from - http://textfiles.com/conspiracy/ is one of many interesting places to pull a corpus from.
What are Markov Chains?
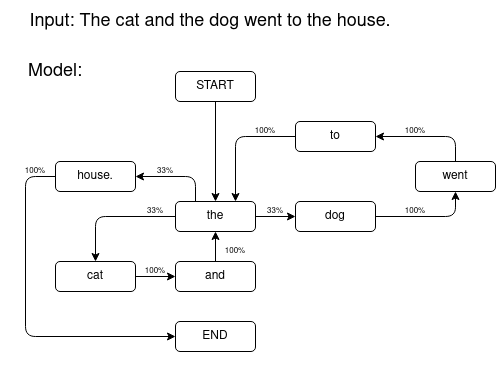
I don't claim to be an expert on the formal mathematical definition or other applications for Markov Chains, but the core concept is that there is some finite set of states, here, words, and transition rules for how likely it is that you will transition from one state to another, here, how likely is it that one word is to follow another in the input body of text. As you can see in the simple example below, there are three possible transitions from the 'the' state, which are equally weighted due to their each having occured once out of three times 'the' appeared in the input text.
C++ Implementation
The std::map type is a powerful associative container which allows you to keep key-value pairs, but you're not limited on what the types of those keys or values are. In this program the entirety of the model is declared with the following:
sstd::map < std::string, std::map < std::string, int > > model;
Which is basically saying that I have a map where the key is a string, and the value is a map of strings to integers. This is a compact representation to keep a count of how many times a given word has followed another word. I read in some body of text, and while I am processing this as input, I keep two strings - the most recently read in string, and the previously read in string. To keep a record of the fact that I have seen one word follow another, I increment the model to indicate that there is some chance that they will occur near each other in the text. Probably expressed more succinctly:
void countWords ( std::ifstream in ) {
std::string curr, prev;
in >> curr;
prev = std::string( "START" );
//create the model
do {
++model[ prev ][ curr ];
prev = curr;
} while ( in >> curr );
}
I don't claim that this is the best representation, and there are some things that go unhandled that can lead to segmentation faults when referencing the model for output. But as a quick little toy program, it is an interesting little demo which is available on github. Use the makefile by typing 'make', or simply do 'g++ main.cc' and then run the program with the following:
./a.out < corpus path > < number of words you want >
It has no dependencies other than the STL. It will process the input, generate a model, and then run through the various states until it produces the number of words you specify or until it seg faults. I haven't spent a lot of time tracking down what exactly is happening when it seg faults, but it is a working example and just a small demo so I haven't dug into it.