Weekend Project: Revisiting Bitfonts
I was struck with the desire to make some kind of art thing this weekend. I got in my head this idea that you could look at each of these fonts and compute a fill percentage, that is, the number of 1's in the bit pattern, divided by the total number of bits in the pattern. This gives you an idea of how 'full' this pattern is, how much it is colored in.

In the process of setting up for this, I wanted to clean up everything and make sure that I had extracted all the distinct font glyphs from the input data. I also wanted to make sure I had some reusable tools in order to wrangle it again, in the event that I found more. I had previously gotten a total count of roughly 56k glyphs, and thought that I had gotten everything. Going through individual fonts this time, I was noticing that some glyph counts weren't adding up. After adding some debug code, printing both glyphs when it found a duplicate, I found that I had made a very dumb little error in the overloaded equality operator which was creating more than 14,000 false positive duplicates. The code to process and condition the data had been kind of hacked up a few times, in order to do a few different things - I rewrote each piece as its own separate file to make it less confusing ( note that each of the referenced .cc files on this page are available in the repo ). After fixing the bug, and grabbing all the original font glyphs extracted from the 918 bitmap fonts ( plus one, that had been added to the parent repo since I forked it ), I wrote sanitize.cc, which will load all the font glyphs and run the roughly 20 minute process of removing invalid glyphs and running the N to N checking for duplicates in the list ( this is where the execution time comes from, as there ended up being more than 250k cantidate glyphs ). Since this is a one-shot operation running on my own hardware I didn't really see much purpose in spending time optimizing by registering the glyphs to a hashmap or so.
Another change I made was to revise the way I was encoding the glyph data. Instead of using strings which consist of '.' for 0, and '@' for 1, making for a human readable format resembling the actual glyph in the file, the new format now uses the bits of a single uint64_t to encode each row. I ran through the glyphs and found the largest row was 42 bits long, so this ended up being a totally workable constraint. This also requires that I at least keep the x dimension per glyph, or else group them in the JSON by width, because it is impossible to determine glyph width from the bit pattern alone ( think 58 leading zeroes in a uint64_t for a width 8 glyph ). When compared to the previous encoding, the total size went from about 18 megabytes to about 7 megabytes. I'm creating another CC0 licensed repo, bitfontCore, that contains just the minimal dataset, loader, etc, but without all the original font files, so it's less bloat to include in projects going forward. You can see the new rectangle packing visualization of all 70,659 bit patterns below. Click to view the image directly for the full 2981 x 4657 image of all the glyphs.

As soon as the issues with the data were all ironed out, I went back to the original idea of finding a use for this fill percentage. I went through and created a list of all the different glyph dimensions that were present in the input data. I wanted to find a size, or set of sizes, for which the glyphs would have a good distribution of fill percentage. What this means is that there are glyphs present in the set which create good coverage over the range 0-100% filled, and if you were to create bins by percentage ( 0-10%, 10-20%, ... ), putting the glyphs into the bins, you'd have some in each bin. Shown below are a few outputs from distribution.cc which shows glyph sizes that exhibit good coverage by 10% bins:
8 by 8 showed up 9557 times | 451 | 1517 | 2714 | 2020 | 1129 | 508 | 293 | 542 | 290 | 92 | 6 by 8 showed up 1945 times | 98 | 273 | 610 | 467 | 95 | 159 | 131 | 72 | 37 | 2 | 8 by 16 showed up 2412 times | 235 | 626 | 470 | 437 | 271 | 147 | 71 | 17 | 79 | 58 | 8 by 12 showed up 2696 times | 322 | 1102 | 637 | 322 | 41 | 51 | 23 | 22 | 136 | 39 | 7 by 8 showed up 729 times | 26 | 105 | 169 | 149 | 50 | 19 | 54 | 98 | 42 | 16 |
That all may sound pretty arbitrary, but you'll understand in a second how this was used. The file gray.cc contains the code which made use of the data in this way. This program loads some arbitrary RGB input image, and processes it to create an output image, which is scaled by a selected glyph size ( I used 8 by 8 for the images below, so x and y are scaled by 8 ). The processing step looks at each channel of each pixel in the input image, and picks three glyphs - one with a fill percentage that maps to the intensity of the red channel, one for the green, and one for the blue. The output image is then constructed, taking these glyphs for red, green, and blue data, putting 255 in the alpha channel. This ends up looking kind of like an interesting type of dithering.
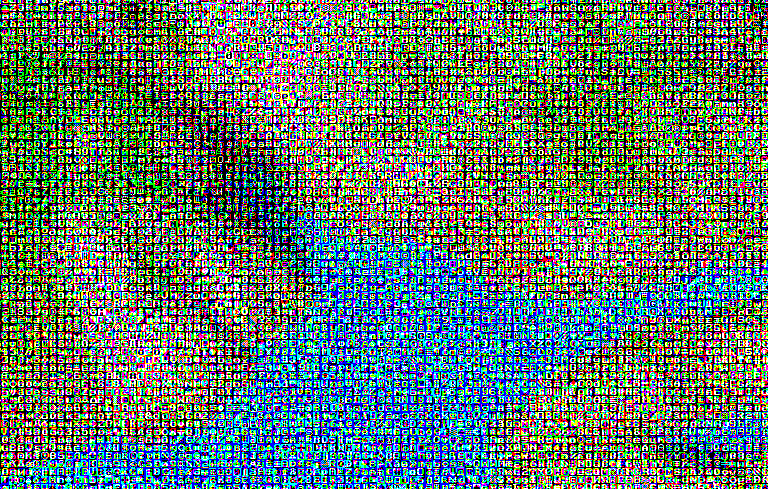
And this works on whatever arbitrary image you want to use. I have tried running it recursively, that is, running it again on the output, but all the local variation in the image really does not play well with png compression, and you are quickly looking at very large, gigabyte+ size outputs.

I have put together a small demo project, to make it easier for others to interact with this dataset, and create something with it. It contains the code to load the glyphs into a std::vector, create an image, randomly stamp them into the image with std::random, and output it as a PNG image using LodePNG. I designed this to be as easy to interact with as possible, and a makefile is provided. You can find the directory here. The demo project will be included in the bitfontCore repository, as well.

In addition to this most recent project, you can see another use case in my writeup on the Voraldo Spaceship Generator. You can read more detail on that page, but that project uses them in a voxel context as these extruded stamps, and operates on them by mirroring, flipping, etc, as you can see in the image above.
Future Directions
This data has a huge amount of potential, endless really, and I will certainly be doing more with it. I am going to rewrite the existing spaceship generator code and include it in bitfontCore, and bitfontCore will be what's included as a submodule in NQUADE instead of the whole hoard-of-bitfonts repo. The existing repo has become large enough to do something about, this new version will just be 7 megabytes for the data and a few k of code.
sanitize.cc- data conditioning, removal of invalid and duplicate glyphsdistribution.cc- counts the number of glyph sizes in the data, and bins them by fill percentagerectPack.cc- generates the rectangle packing visualization shown aboveuintLoader.cc- shows the most basic loading of the uint64_t packed datagray.cc- image processing code to generate images like on this page- The demo project - starting point for others who might want to interact with the data
I have two projects in the ideation phase, which will be making use this data. The first is something to generate some glitch aesthetic stuff, by using these bit patterns as masks for different operations on some image data, maybe doing this in a tile-based renderer, with different behavior per tile. This would be some different things like:
- Blurring
- Clearing
- Clearing every other row or column
- Adding static, different types of noise
- Resetting the accumulated sample count to 1
- Apply dithering
- Grab floats, cast as uint8_t bytes in a std::vector, shuffle, cast back to floats
Which might make for some interesting visual artifacts. I think this is worth pursuing, for one of my existing pathtracer projects, or maybe something else.
The second idea is related to pen plotting - I am waiting for delivery of an Axidraw SE/A3 pen plotter, which is in essense an armature with a 2d travel, and a servo to lift and drop a pen held at a precisely located point. This can be used with an Inkscape plugin to draw strokes out of SVG drawings, or controlled directly via command line. SVG is a vector format, which is different than what I usually work with - this will be an interesting new context to explore and see what is possible with. My first thought for using the font glyphs with the plotter is to generate something like one of the above visualizations, and then sweep across by the rows in the raster, lifting and dropping the pen in order to trace out lines across, in places where you are 'on the glyph'. More to come on this project as it develops.